Online disinformation is a hard problem that lies at the center of social interaction, human behavior and belief, technology, and nation-state intelligence operations; it would be nice to be able to design an intervention that could stop its spread. Unfortunately, this has proven less than straightforward. To take a stab at identifying if current research on this topic contains evidential value, we conduct a (pre-registered) p-curve analysis (as introduced by Simonsohn et al.) on a subset of the bibliography of Courchesne et al.’s review of counter-disinformation literature, hypothesizing that current disinformation research does not contain evidential value. . As our selection criteria, we chose only studies that find that a particular direct, demand-side intervention against disinformation to be successful. By “direct” and “demand-side”, we mean an intervention that is aimed at a potential target of disinformation – an average user – and which is implemented just before, at the same time as, or just after the target interacts with the disinformation. For example, qualifying interventions include things like fact-checking a news headline and labeling the funding source of state-run media videos. An example of a “non-direct” intervention would be a media-literacy education program, since it is implemented significantly before potential interaction with disinformation. An example of a “supply-side” intervention would be de-platforming social media users who spread disinformation, since it aims to make it harder for a malicious actor to spread disinformation to a target rather than easier for a target to identify disinformation and act appropriately. Originally, I was aiming to compare studies that found the intervention to be effective with studies that found the intervention neutral. However, it turns out that, contrary to my assumptions, studies that claimed (in their abstract/title) to find that an intervention was not effective actually just failed to find evidence that it was effective. These were still potentially interesting results in my view, but not useful for making a p-curve.
Using this selection criteria, out of the 51 in the bibliography, we found 12 articles which met this criteria. Unfortunately, we were forced to reject a 6 of those for a few reasons. First, some did not have a clear, stated hypothesis, which meant that any reported p-values could not be included in a p-curve analysis. Second, some did not have a clear statistical result which was tied to a stated hypothesis. In a few cases where the exact tests used and specific p-values were not reported, we recalculated statistical tests from the original data if available (although in these two cases, the original analysis was done in Strata, with which I am not familiar and the code of which is exceedingly esoteric; I did my best to infer what tests they used and recalculated them in R). The final list of p-values I collected from these 6 papers includes 11 p-values across 9 studies (many papers tested multiple hypotheses and conducted multiple experiments).
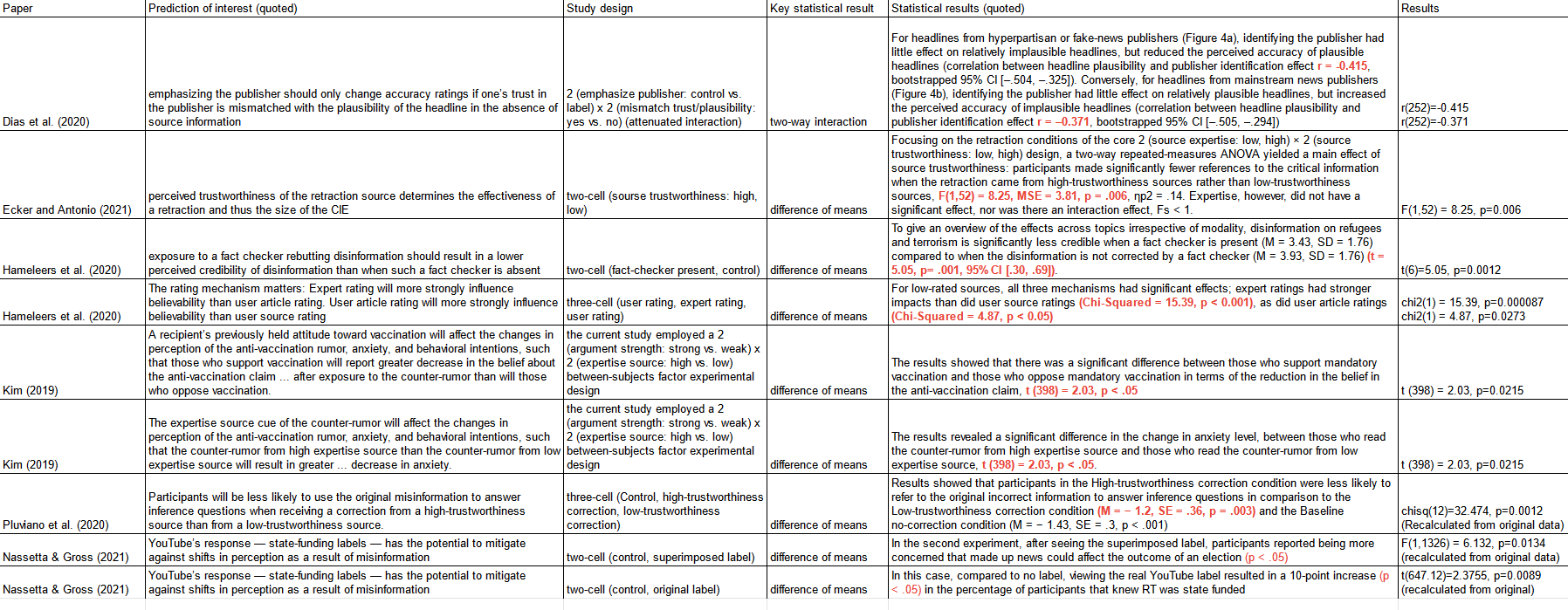
Feeding our statistics into the p-curve web app, we find the following curve.
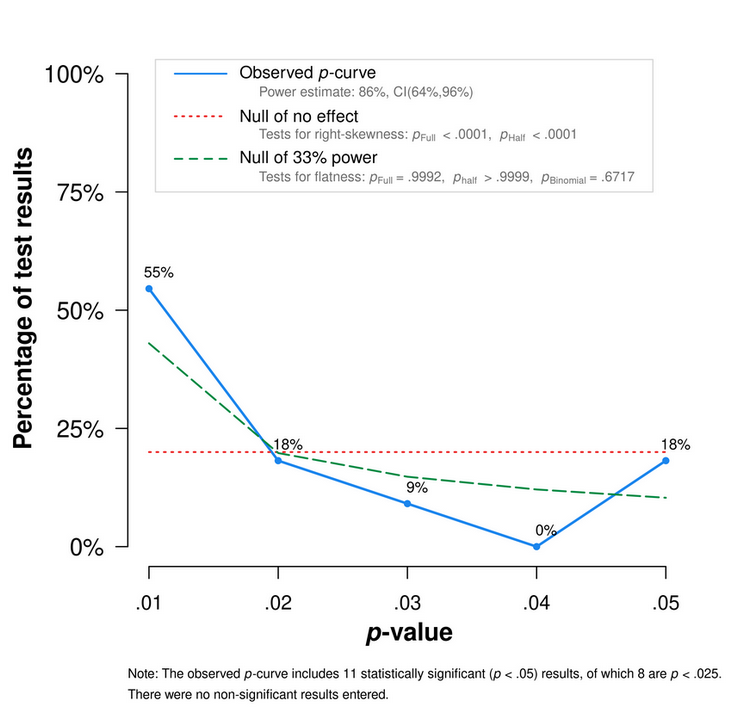
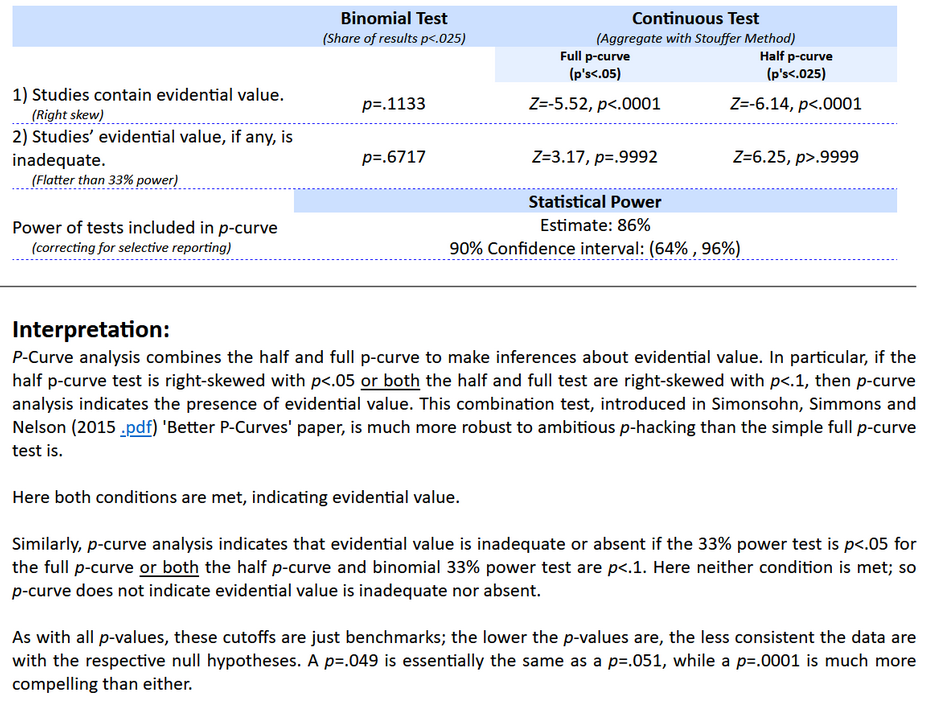
This curve seems to imply some amount of evidential value, but perhaps not as much as would be expected, especially given that most of these studies should be quite high powered (relying on hundreds or thousands of participants). We do notice that the two p-values which skew the curve towards the 0.05 side are both from Kim and are both identical with t(398)=2.03. It seems plausible that either I misinterpreted the paper at some point or that this was a typo. For the sake of exploration, we remade our p-curve without these two studies.
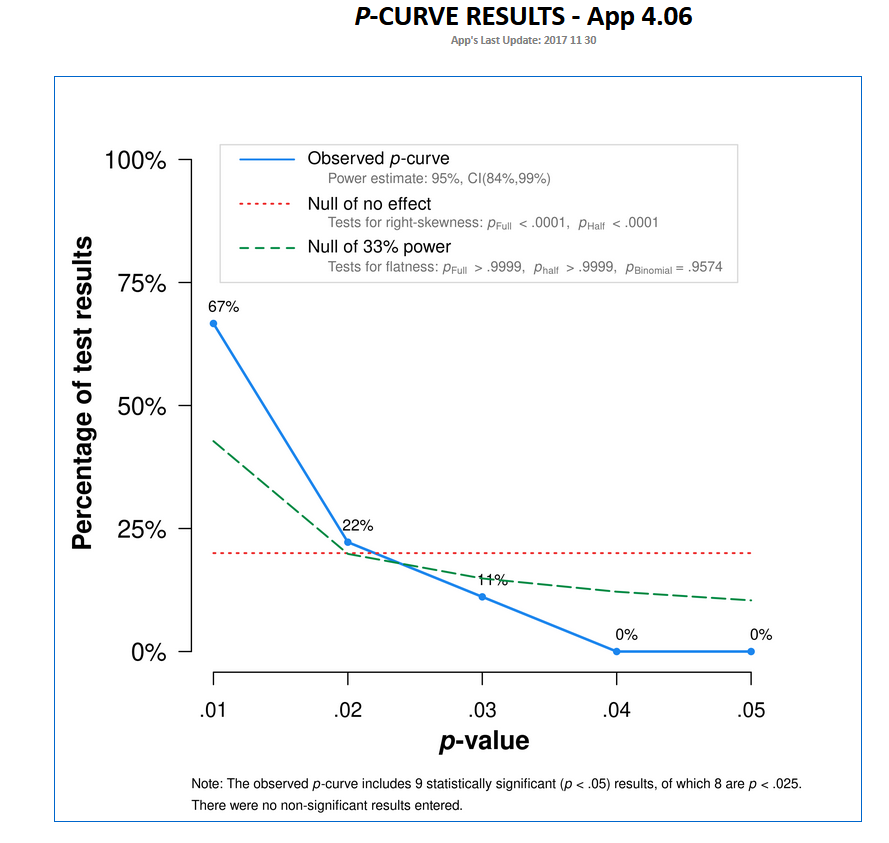
This curve certainly seems to imply more evidential value, but with our post-hoc fiddling, we can’t conclude anything with a lot of confidence.
Ultimately, the conclusion I take from this research actually has nothing to do with whether or not current disinformation research has evidential value. In reading a bunch of these papers, it seems unlikely to me that there is a lot of p-hacking going on and likely that there actually is pretty good research methodology. However, I am not convinced that the research contains a lot of useful theoretical findings that can help design counter-disinformation interventions generally. The picture that emerges for me is (in what is perhaps unsurprising) one of remarkable non-linearity and massively dimensional input space. Nassetta and Gross’s paper is a prime example of this picture. They find a significant difference in effect between two different labels placed on disinformation videos which differ only in color:
The difference in mitigation between the real label as implemented by YouTube and our superimposed version suggests that the correction effects are dependent on the label being noticed and the information in it being absorbed. The rate at which this happens is strongly dependent on the placement and subtlety of the label. In the time between the first and second experiments, YouTube slightly changed the implementation of their label. The language remained the same, but the color changed from a light grey that blended with the YouTube interface to a more prominent blue. This change alone resulted in a 15-point increase in those reporting having noticed the label and a corresponding increase in those that reported knowing that RT was state funded.”
The papers I read were rife with examples of the way small changes in the content, design, and context of the intervention had drastic changes on the effectiveness of an intervention. The sense I get is that all of this research, even if done methodologically perfect, is like a ship in a trough of a wave (in a hyper-dimensional ocean?), claiming that it has found the global minimum of the ocean. Certainly, you may have actually found the lowest point in the Gulf of YouTube, but it’s unclear if saying this helps us find low points in the Twitter Strait (wow, I really apologize for this metaphor, it is way to conceited but I think it works). I feel like causal inference in this field is too premature to be helpful. In my opinion, more explicitly exploratory analysis is necessary. In fact, most of the papers I read felt much more like they were exploratory analysis – testing out a bunch of different possible ideas about what can mitigate disinformation – that conformed itself into the shape of causal inference. While the causal inference may be sound methodologically, it risks making the public and policymakers overestimate the generalization and applicability of the results, especially since many of these kinds of interventions are being actively implemented by tech companies, governments, and others.